Generate Elixir API Docs with Bureaucrat
This is a tutorial to setup Bureaurcrat and Swagger API documentation with an Elixir project. The only way to make sure documentation stays up to date is to generate it automatically. Since Bureaucrat is a popular ruby tool, I will briefly cover Elixir then dive into code.
First, a (very) brief introduction to Elixir
Elixir is an efficient, readable, and scaleable language; perfect for building an API. It is designed to be fault tolerant, using individually silo’ed processes to prevent isolated errors from causing app-wide errors. The most popular framework to build application in Elixir is Phoenix, which is designed to feel just like Rails. Elixir compiles to erlang, which is an (relatively) ancient language which first appeared in 1986 per wikipedia. It took 30 years to figure out its value, but now with its fresh Elixir wrapper and Ruby-ish syntax it is has become a cornerstone of large companies everywhere.
I will leave the details about just how much faster/more efficient Elixir is than Ruby to more qualified professionals, but wanted to briefly introduce the subject for readers who might not have the background.
What is Bureaucrat?
Bureaucrat is a dependency you can add to your Phoenix project which will use your tests (yes, you have to write tests…) to automatically compile api documentation. As endpoints are added or changed, this handy tool will re-generate markdown (or HTML with some customization) so nobody has the unenviable task of making sure documentation is up to date.
The package lacks proper documentation and following the readme on github will inevitably lead you astray. That confusion is what inspired me to take a moment to organize my thoughts here in hopes that it helps someone else avoid some rather annoying shortcomings.
Basic implementation
Bureaucrat can write basic markdown with the simple built in markdown writer. The configuration looks as follows:
# in test/test_helper.exs
Bureaucrat.start(
writer: Bureaucrat.MarkdownWriter,
default_path: "docs/api-v1.md",
paths: [],
titles: [
{ApplicationCartController, "API /carts"},
{Canvaserver.V1.RouteController, "API /routes"},
{Canvaserver.V1.WaypointController, "API /waypoints"},
{Canvaserver.V1.ChargerController, "API /chargers"}],
env_var: "DOC"
)
# titles add extra metadata to alias controllers
# add Bureaucrat formatter to ExUnit.start()
ExUnit.start(formatters: [ExUnit.CLIFormatter, Bureaucrat.Formatter])
Now, all we need to do is add a documentation call to endpoint tests which we want to be documented, and our basic documentation is done!
conn = conn
|> api_login(user) # helper method
|> get(v1_cart_path(conn, :index))
|> doc(description: "List all carts")
# description is an extra option for basic metadata with the basic bureaucrat implementation
# calling tests, include the DOC=1 flag to trigger bureaucrat
DOC=1 mix test
Any file saved in the destination folder with _intro will automatically be included at the head of the output file, so you can customize a bit.
This is as good as it gets with Bureaucrats built in markdown writer.
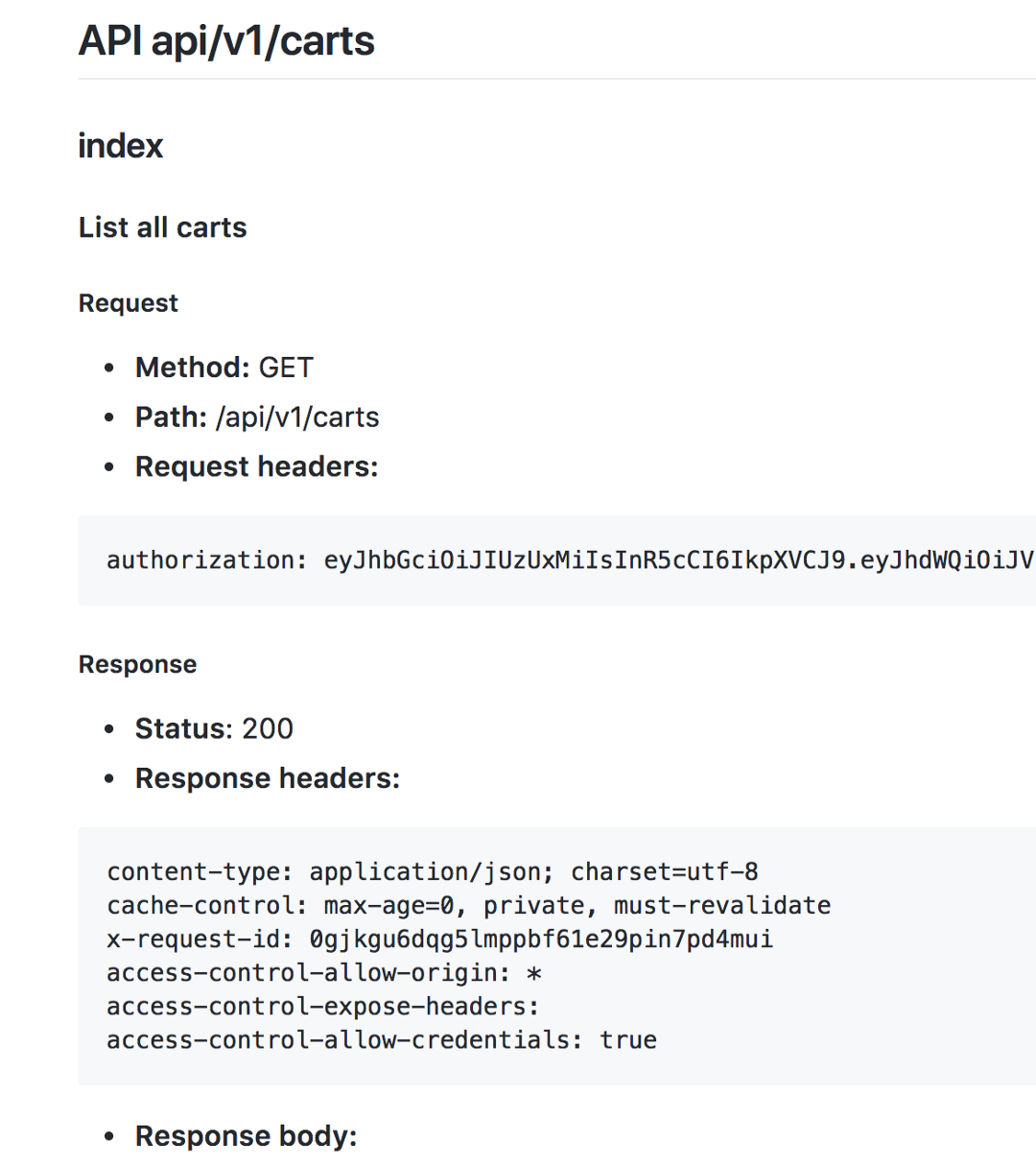
Bureaucrat with Swagger and Slate
Bureaucrat offers a second option to generate documentation with SwaggerSlateMarkdown writer. The configuration of this approach looks something like this:
Bureaucrat.start(
writer: Bureaucrat.SwaggerSlateMarkdownWriter,
default_path: "ext/doc/source/index.html.md",
swagger: "swagger.json" |> File.read!() |> Poison.decode!()
)
# default_path points to a cloned slate project
# swagger points to a generated swagger.json file
ExUnit.start(formatters: [ExUnit.CLIFormatter, Bureaucrat.Formatter])
Swagger follows open API syntax, or generally accepted language to document the purpose and use of an API. PhoenixSwagger allows us to populate this metadata in our controllers and execute a command to generate the swagger.json file. Steps to install can be found at the link above, but here is an example of how it is used.
# import PhoenixSwagger before using to gain access to swagger_path and swagger_definition methods
use PhoenixSwagger
# define basic get all carts method
swagger_path :index do
get "api/v1/carts"
summary "Query for carts"
description "Query returns all carts"
produces "application/json"
tag "Carts"
operation_id "list_carts" # used to link to test examples
parameters do
authorization :header, :string, "authorization token", required: true
end
# define expected parameters
response 200, "OK", Schema.ref(:CartsResponse)
response 400, "Client Error"
# define responses
end
We can also define Schemas, so I can simply tell users I will return them an array of Carts and link to the structure of a cart if they are curious.
def swagger_definitions do
CartsResponse: swagger_schema do
title "Carts Response"
description "response template for carts"
properties do
success :boolean, "success boolean", required: true
data :array, "array of carts", items: Schema.ref(:Cart), required: true
end
end
end
# we would then have to define :Cart
These data models are nicely hyperlinked in the output. Assuming everything is properly configured, you can update your swagger.json file by tweaking this script for your project and running.
mix phx.swagger.generate --router Application.Router --endpoint Application.Endpoint
Your swagger.json file should now be populated with all the models defined in swagger_definition statements, all the paths defined in swagger_path statements, and all the examples referenced in your tests.
# ...in tests...
|> doc(operation_id: "list_carts")
# refers to operation_id in swagger_path
The next step is taking that json and transforming it into a beautiful interactive document.
Using Slate with Swagger.json
Slate depends on ruby, bundler, and middleman. This can cause a hickup in the deployment process for some, but for most is just a onetime inconvenience.
The output is a clean and interactive document any developer would be happy to work with.
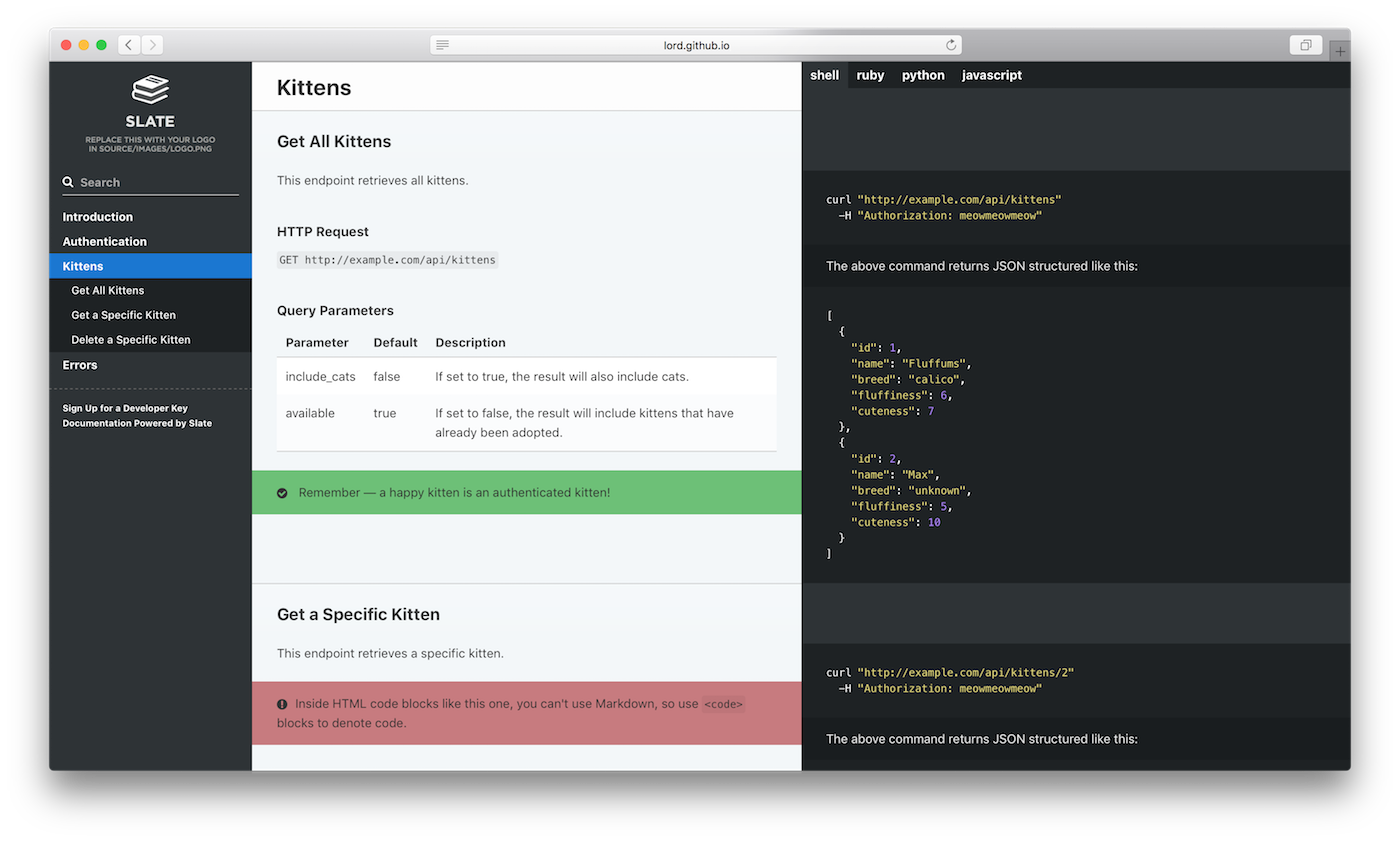
Now, when we include DOC=1 in our test script again Bureaucrat will do 2 things for us:
- update swagger.json with examples from the test library
- update slate index.html.md file with the final contents of swagger.json
All that is left to do is rebuilding the slate repo:
# from /doc/
bundle exec middleman build
You can open up the index.html.md file in the browser and (hopefully) start interacting with your documentation.
To pull it all together
This post got out of hand, but the general idea here is to automate documentation. Helping future developers, particularly yourself, avoid the mundane tasks of updating documentation ensures that those documents stay up to date. Up to date documents ensure that customers and clients can use your services to the best of their abilities, without your business having to handle churn from questions and issues.
As always, feedback is welcome on these posts. If you found anything misleading or confusing please let me know so I can update this post.